
Управление данными
Первое, что вы делаете, создав таблицу, это начинаете добавлять в нее данные. Если данные уже есть, может возникнуть необходимость изменить или удалить их.
Добавление данных
Добавление данных в таблицу является одной из наиболее простых операций SQL. Несколько примеров этого вы уже видели. Как MySQL, так и mSQL поддерживают стандартный синтаксис INSERT:
INSERT INTO table_name (columnl, column2, ..., columnN)
VALUES (value!, value2, .... valueN)
Данные для числовых полей вводятся как они есть. Для всех других полей вводимые данные заключаются в одиночные кавычки. Например, для ввода данных в таблицу адресов можно выполнить следующую команду:
INSERT INTO addresses (name, address, city, state, phone, age)
VALUES( 'Irving Forbush', ' 123 Mockingbird Lane', 'Corbin', 'KY', '(800) 555-1234', 26)
Кроме того, управляющий символ - по умолчанию '\' — позволяет вводить в литералы одиночные кавычки и сам символ '\':
# Ввести данные в каталог Stacie's Directory, который находится
# в c:\Personal\Stacie
INSERT INTO files (description, location)
VALUES ('Stacie\'s Directory', 'C: \\Personal\\Stacie')
MySQL позволяет опустить названия колонок, если значения задаются для всех колонок и в том порядке, в котором они были указаны при создании таблицы командой CREATE. Однако если вы хотите использовать значения по умолчанию, нужно задать имена тех колонок, в которые вы вводите значения, отличные от установленных по умолчанию. Если для колонки не установлено значение по умолчанию и она определена как NOT NULL , необходимо включить эту колонку в команду INSERT со значением, отличным от NULL. В mSQL значение по умолчанию всегда NULL. MySQL позволяет указать значение по умолчанию при создании таблицы в команде CREATE.
Более новые версии MySQL поддерживают нестандартный вызов INSERT для одновременной вставки сразу нескольких строк:
INSERT INTO foods VALUES (NULL, 'Oranges', 133, 0, 2, 39),
(HULL, 'Bananas', 122, 0, 4, 29), (NULL, 'Liver', 232, 3, 15, 10)

MySQL поддерживает синтаксис SQL2, позволяющий вводить в таблицу результаты запроса SELECT:
INSERT INTO foods (name, fat)
SELECT food_name, fat_grams FROM recipes
Обратите внимание, что число колонок в INSERT соответствует числу колонок в SELECT. Кроме того, типы данных колонок в INSERT должны совпадать с типами данных в соответствующих колонках SELECT. И, наконец, предложение SELECT внутри команды INSERT не должно содержать модификатора ORDER BY и не может производить выборку-из той же таблицы, в которую вставляются данные командой INSERT.
Изменение данных
Добавление новых строк в базу данных - лишь начало ее использования. Если ваша база не является базой данных «только для чтения», вам, вероятно, понадобится периодически изменять данные. Стандартная команда SQL для изменения данных выглядит так:
UPDATE table_name
SET column1=value1, column2=value2, ..., columnN=valueN
[WHERE clause]
В mSQL значение, присваиваемое колонке, должно быть литералом и иметь тот же тип, что и колонка. MySQL, напротив, позволяет вычислять присваиваемое значение. Можно даже вычислять значение, используя значение другой колонки:
UPDATE years
SET end_year - begin_year+5
В этой команде значение колонки end_year устанавливается равным значению колонки begin_year плюс 5 для каждой строки таблицы.
Предложение WHERE
Возможно, вы уже обратили внимание на предложение WHERE. В SQL предложение WHERE позволяет отобрать строки таблицы с заданным значением в указанной колонке, например:
UPDATE bands
SET lead_singer = 'Ian Anderson'
WHERE band_name = 'Jethro Tull'
Эта команда — UPDATE - указывает, что нужно изменить значение в колонке lead_singer для тех строк, в которых band_name совпадает с «Jethro Tull.» Если рассматриваемая колонка не является уникальным индексом, предложение WHERE может соответствовать нескольким строкам. Многие команды SQL используют предложение WHERE, чтобы отобрать строки, над которыми нужно совершить операции. Поскольку по колонкам, участвующим в предложении WHERE, осуществляется поиск, следует иметь индексы по тем их комбинациям, которые обычно используются.
Удаление
Удаление данных - очень простая операция. Вы просто указываете таблицу, из которой нужно удалить строки, и в предложении WHERE задаете строки, которые хотите удалить:
DELETE FROM table_name [WHERE clause]
Как и в других командах, допускающих использование предложения WHERE, его использование является необязательным. Если предложение WHERE опущено, то из таблицы будут удалены все записи! Из всех удаляющих данные команд SQL эта легче всего может привести к ошибке.
Запросы
Самая часто используемая команда SQL - та, которая позволяет просматривать данные в базе: SELECT. Ввод и изменение данных производятся лишь от случая к случаю, и большинство баз данных в основном занято тем, что предоставляет данные для чтения. Общий вид команды SELECT следующий:
SELECT column1, column2, ..., columnN
FROM table1, table2, .... tableN
[WHERE clause]
Этот синтаксис, несомненно, чаще всего используется для извлечения данных из базы, поддерживающей SQL. Конечно, существуют разные варианты для выполнения сложных и мощных запросов, особенно в MySQL. Мы полностью осветим синтаксис SELECT в главе 15.
В первой части команды SELECT перечисляются колонки, которые вы хотите извлечь. Можно задать «*», чтобы указать, что вы хотите извлечь все колонки. В предложении FROM указываются таблицы, в которых находятся эти колонки. Предложение WHERE указывает, какие именно строки должны использоваться, и позволяет определить, каким образом должны объединяться две таблицы.
Объединения
Объединения вносят «реляционность» в реляционные базы данных. Именно объединение позволяет сопоставить строке одной таблицы строку другой. Основным видом объединения является то, что иногда называют внутренним объединением. Объединение таблиц заключается в приравнивании колонок двух таблиц:
SELECT book, title, author, name
FROM author, book
WHERE book, author = author, id
Рассмотрим базу данных, в которой таблица book имеет вид, как в таблице 6-3.
Таблица 6-3. Таблица книг
ID |
Title |
Author |
Pages |
||
1 |
The Green Mile |
4 |
894 |
||
2 |
Guards, Guards! |
2 |
302 |
||
ID |
Title |
Author |
Pages |
||
3 |
Imzadi |
3 |
354 |
||
4 |
Gold |
1 |
405 |
||
5 |
Howling Mad |
3 |
294 |
||
Таблица 6-4. Таблица авторов
ID |
Name |
Citizen |
||
1 |
Isaac Asimov |
US |
||
2 |
Terry Pratchet |
UK |
||
3 |
Peter David |
us |
||
4 |
Stephen King |
us |
||
5 |
Neil Gaiman |
UK |
||
Таблица 6-5. Результаты запроса с внутренним объединением
Book Title |
Author Name |
||
The Green Mile |
Stephen King |
||
Guards, Guards! |
Terry Pratchet |
||
Imzadi |
Peter David |
||
Gold |
Isaac Asimov |
||
Howling Mad |
Peter David |
||
Псевдонимы
Полные имена, содержащие имена таблиц и колонок, зачастую весьма громоздки. Кроме того, при использовании функций SQL, о которых мы будем говорить ниже, может оказаться затруднительным ссы-
латься на одну и ту же функцию более одного раза в пределах одной команды. Псевдонимы, которые обычно короче и более выразительны, могут использоваться вместо длинных имен внутри одной команды SQL, например:
# Псевдоним колонки
SELECT long_field_names_are_annoying AS myfield
FROM table_name
WHERE myfield = 'Joe'
# Псевдоним таблицы в MySQL
SELECT people.names, tests.score
FROM tests, really_long_people_table_name AS people
# Псевдоним таблицы в mSQL
SELECT people.names, tests.score
FROM tests, really_long_people_table_name=people
mSQL полностью поддерживает псевдонимы для таблиц, но не поддерживает псевдонимы для колонок.
Группировка и упорядочение
По умолчанию порядок, в котором появляются результаты выборки, не определен. К счастью, SQL предоставляет некоторые средства наведения порядка в этой случайной последовательности. Первое средство -упорядочение - есть и в MySQL, и в mSQL. Вы можете потребовать от базы данных, чтобы выводимые результаты были упорядочены по некоторой колонке. Например, если вы укажете, что запрос должен упорядочить результаты по полю last_name , то результаты будут выведены в алфавитном порядке по значению поля last_name . Упорядочение осуществляется с помощью предложения ORDER BY:
SELECT last_name, first_name, age
FROM people
ORDER BY last_name, first_name
В данном случае упорядочение производится по двум колонкам. Можно проводить упорядочение по любому числу колонок, но все они должны быть указаны в предложении SELECT. Если бы в предыдущем примере мы не выбрали поле last_name , то не смогли бы упорядочить по нему.
Группировка — это средство ANSI SQL, реализованное в MySQL, но не в mSQL. Поскольку в mSQL нет агрегатных функций, то группировка просто не имеет смысла. Как и предполагает название, группировка позволяет объединять в одну строки с аналогичными значениями с целью их совместной обработки. Обычно это делается для применения к результатам агрегатных функций. О функциях мы поговорим несколько позднее.
Рассмотрим пример:
mysql> SELECT name, rank, salary FROM people\g
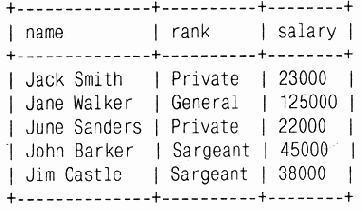
5 rows in set (0.01 sec)
После группировки по званию (rank) выдача изменяется:
mysql> SELECT rank FROM people GROUP BY rank\g
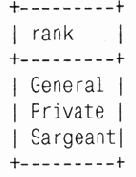
3 rows in set (0.01 sec)
После применения группировки можно, наконец, найти среднюю зарплату (salary) для каждого звания. О функциях, используемых в этом примере, мы поговорим позднее.
mysql> SELECT rank, AVG(salary) FROM people GROUP BY rank\g

3 rows in set (0.04 sec)
Мощь упорядочения и группировки в сочетании с использованием функций SQL позволяет производить большой объем обработки данных на сервере до их извлечения. Но этой мощью нужно пользоваться с большой осторожностью. Хотя может показаться, что перенос максимального объема обработки на сервер базы данных дает выигрыш в производительности, на самом деле это не так. Ваше приложение-клиент обслуживает потребности отдельного клиента, в то время как сервер совместно используется многими клиентами. Из-за большого объема работы, который должен производить сервер, почти всегда более эффективно возложить на сервер минимально возможную нагрузку. MySQL и mSQL, возможно, наиболее быстрые из имеющихся баз данных, но не нужно использовать эту скорость для той работы, к которой лучше приспособлено клиентское приложение.
Если вам известно, что много клиентов будет запрашивать одни и те же итоговые данные (например, данные по некоторому званию в нашем предыдущем примере), создайте новую таблицу с этими данными и обновляйте ее при изменении данных в исходной таблице. Эта операция аналогична буферизации и является распространенным приемом в программировании баз данных.