
Нормализация
Е. Ф. Кодд (Е. F. Codd), занимавшийся исследовательской работой в IBM, впервые представил концепцию нормализации в нескольких важных статьях, написанных в 1970-е годы. Задача нормализации остается той же самой и сегодня: устранить из базы данных некоторые нежелательные характеристики. В частности ставится задача устранить некоторые виды избыточности данных и благодаря этому избежать аномалий при изменении данных. Аномалии изменения данных - это сложности при операциях вставки, изменения и удаления данных, возникающие из-за структуры базы данных. Дополнительным результатом нормализации является конструкция, хорошо соответствующая реальному миру. Поэтому в результате нормализации модель данных становится более ясной.
Например, предположим, что мы ошиблись при вводе «Herbie Hancock» в нашу базу данных и хотим исправить ошибку. Нам потребовалось бы рассмотреть все диски этого исполнителя и исправить имя. Если изменения производятся с помощью приложения, позволяющего одновременно редактировать только одну запись, нам придется редактировать много строк. Было бы гораздо лучше запомнить имя «Herbie Hancock» лишь один раз и редактировать его в одном месте.
Первая нормальная форма (1NF)
Общее понятие нормализации подразделяется на несколько «нормальных форм». Говорят, что сущность находится в первой нормальной форме, когда все ее атрибуты имеют единственное значение. Чтобы признать сущность находящейся в первой нормальной форме, нужно удостовериться в том, что каждый атрибут сущности имеет единственное значение для каждого экземпляра сущности. Если в каком-либо атрибуте есть повторяющиеся значения, сущность не находится в 1NF.
Вернувшись к нашей базе данных, мы обнаруживаем, что повторяющиеся значения есть в атрибуте Song (песня), поэтому очевидно, что база не находится в 1NF. Сущность с повторяющимися значениями указывает на то, что мы упустили еще по крайней мере одну сущность. Обнаружить другие сущности можно, взглянув на каждый атрибут и задавшись вопросом «что описывает эта вещь?»
Что описывает атрибут Song? Он перечисляет все песни на CD. Поэтому Song - это еще один объект, о котором мы собираем данные, и, возможно, он является сущностью. Мы добавим его в свою диаграмму и придадим атрибут Song Name (название песни). Чтобы покончить с сущностью Song, спросим себя, чем еще мы хотели бы ее охарактеризовать. Мы отметили ранее, что длительность песни мы также хотели бы сохранить. Новая модель данных показана на рис. 2-3.
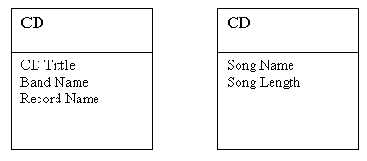
Рис. 2-3. Модель данных с сущностями CD и Song
Теперь, когда Song Name и Song Length являются атрибутами сущности Song, мы имеем модель данных с двумя сущностями в 1NF. К сожалению, мы не указали никакого способа связать вместе CD и Song.
Уникальный идентификатор
Прежде чем обсуждать связи, мы должны применить к сущностям еще одно правило. У каждой сущности должен быть однозначный идентификатор, который мы будем называть ID. ID есть атрибут сущности, к которому применимы следующие правила:
ID очень важен, поскольку позволяет узнать, с каким из экземпляров сущности мы имеем дело. Выбор идентификатора также существенен, потому что он используется для моделирования связей. Если после выбора ID для сущности вы обнаружили, что он не удовлетворяет одному из перечисленных правил, это может повлиять на всю вашу модель данных.
Новички в моделировании данных часто делают ошибку, выбирая в качестве ID неподходящие атрибуты. Если, к примеру, у вас есть сущность Person (человек, лицо), может возникнуть соблазн выбрать в качестве идентификатора Name (фамилию), поскольку она есть у каждого лица и не меняется. Но что если лицо вступает в брак или законным образом хочет изменить фамилию? Или вы допустили ошибку при первоначальном вводе фамилии? При каждом из этих событий нарушается третье правило для идентификаторов. Еще хуже то, что фамилия окажется не уникальной. Если вы не можете стопроцентно гарантировать, что атрибут Name уникален, вы нарушаете первое правило для идентификаторов. Наконец, вы считаете, что у каждого экземпляра Person фамилия отлична от NULL. Но вы уверены, что всякий раз, вводя первоначальные данные в базу, будете знать фамилию? Ваш процесс может быть организован так, что при начальном создании записи фамилия может быть неизвестна. Из этого следует извлечь тот урок, что при выборе неидентифицирующего атрибута в качестве идентификатора возникает много проблем.
Выход в том, чтобы изобрести идентифицирующий атрибут, не имеющий никакого иного смысла, кроме как служить идентифицирующим атрибутом. Поскольку этот атрибут искусственный и никак не связан с сущностью, мы имеем над ним полный контроль и можем обеспечить его соответствие правилам для уникальных идентификаторов. На рис. 2-4 к каждой из наших сущностей добавлен искусственный ID. На диаграмме уникальный идентификатор изображается как подчеркнутый атрибут.
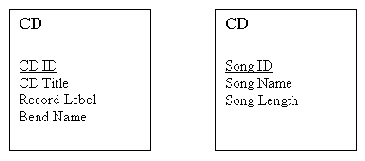
Рис. 2-4. Сущности CD и Song со своими уникальными идентификаторами
Связи
Идентификаторы наших сущностей позволяют моделировать их связи. Связь описывает бинарное отношение между двумя сущностями. Связь может существовать также внутри одной сущности. Такая связь называется рекурсивной. Каждая сущность, участвующая в связи, описывает-другую и описывается ею. Каждая сторона связи имеет две составляющих - имя и степень.
У каждой стороны связи есть имя, описывающее связь. Возьмем две гипотетические сущности — Служащий и Отдел. Один вариант связи между ними состоит в том, что Служащий «приписан» к Отделу. Этот Отдел «отвечает» за Служащего. Таким образом, связь со стороны Служащий называется «приписан», а со стороны Отдел - «отвечает».
Степень, называемая также кардинальным числом, показывает, сколько экземпляров описывающей сущности должны описывать один экземпляр описываемой сущности. Степень выражается с помощью двух разных значений- «один-к-одному» (1) и «один-ко-многим» (М). Служащий приписан одновременно только к одному отделу, поэтому у сущности Служащий связь с сущностью Отдел «один-к-одному». В обратном направлении, отдел отвечает за многих служащих. Поэтому мы говорим, что у сущности Отдел связь с сущностью Служащий «один-ко-многим». В результате в Отделе может быть и только один Служащий.
Иногда полезно выразить связь словами. Один из способов - вставить разные составляющие направления связи в следующую формулу:
сущность1имеет [одну и только одну одну или много] сущностъ2
Согласно этой формуле связь между Служащим и Отделом можно выразить так:
Каждый Служащий должен быть приписан к одному и только одному
Отделу.
Каждый Отдел может отвечать одному или многим Служащим.
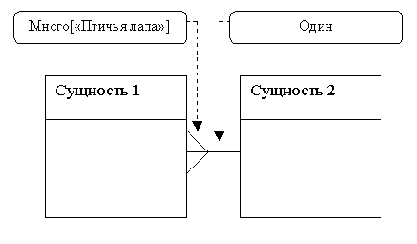
Рис. 2-5. Анатомия связи
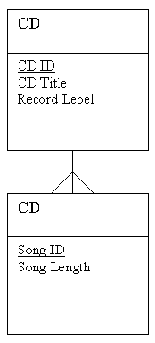
Рис. 2-6. Связь CD-'Song
Можно использовать эту формулу для описания сущностей в нашей модели данных. В каждом CD содержится много или одна Song, и каждая Song содержится хотя бы в одном CD. В нашей модели данных эту связь можно показать, проведя линию между двумя сущностями. Степень обозначается прямой линией для связи «один и только один» и «птичьей лапой» для связи «один-ко-многим>>. На рис. 2-5 показаны эти обозначения.
Как это применимо к связи между Song и CD? На практике Song может содержаться на многих CD, но для нашего примера мы этим пренебрежем. На рис. 2-6 показана модель данных с обозначенными связями.
Прочно установив связи, мы можем вернуться к процессу нормализации и опять улучшить нашу схему. Пока мы лишь нормализовали повторяющиеся песни, преобразовав их в отдельную сущность, и смоделировали связь между ней и сущностью СD.
Вторая нормальная форма (2NF)
Говорят, что сущность находится во второй нормальной форме, если она уже находится в первой НФ, и каждый неидентифицирующий атрибут зависит от всего уникального идентификатора сущности. Если некий атрибут не зависит полностью от уникального идентификатора сущности, значит, он внесен ошибочно и должен быть удален. Нормализуйте такой атрибут либо найдя сущность, к которой он относится, либо создав новую сущность, в которую он должен быть помещен.
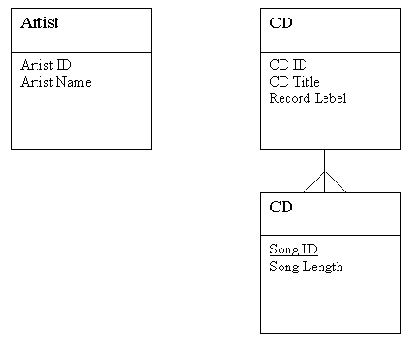
Рис. 2-7. Модель данных с новой сущностью Artist
В нашем примере «Herbie Hancock» является Band Name (названием ансамбля) для двух разных CD. Это показывает, что Band Name не полностью зависит от идентификатора CD ID. Это дублирование представляет собой проблему, поскольку если мы допустили ошибку при вводе «Herbie Hancock», придется исправлять значение в нескольких местах. Это указывает нам, что Band Name должно быть частью новой сущности, связанной с CD. Как и раньше, мы решаем эту задачу, задав вопрос: «Что описывает название ансамбля?» Оно описывает ансамбль, или, вообще говоря, исполнителя. Исполнитель - еще один объект, о котором мы собираем данные, и потому, возможно, является сущностью. Мы добавим его к нашей схеме с атрибутом Band Name. Поскольку исполнитель может не быть ансамблем, мы переименуем атрибут как Artist Name. На рис. 2-7 показано новое состояние модели.
Правда, не показаны связи для новой таблицы исполнителей. Ясно, что у каждого Artist может быть один или много CD. У каждого CD может быть один или несколько Artist. Это показано на рис. 2-8.
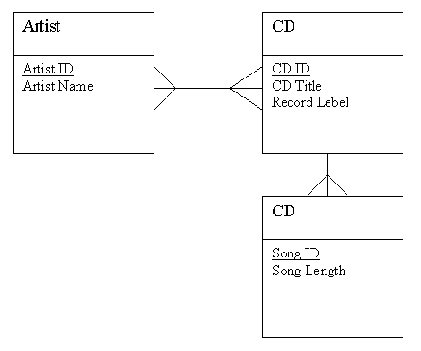
Рис. 2-8. Связи сущности Artist в модели данных
Вначале мы присвоили атрибут Band Name сущности CD. Поэтому было естественным установить прямую связь между Artist и CD. Но верно ли это? При ближайшем рассмотрении оказывается, что следует установить прямую связь между Artist и Song. У каждого Artist есть одна или много Song. Каждая Song исполняется одним и только одним Artist. Правильные связи показаны на рис. 2-9.
Это не только более разумно, чем связь между Artist и CD, но и решает проблему дисков-сборников.
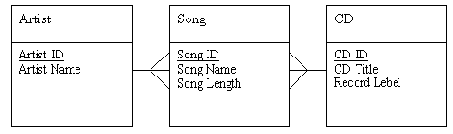
Рис. 2-9. Подлинная связь между Artist и остальной частью модели данных
Виды связей
При моделировании связей между сущностями важно определить оба направления связи. После определения обеих сторон связи мы приходим к трем основным видам связей. Если оба конца связи имеют степень «один и только один», то связь называется «один-к-одному». Как мы позднее убедимся, связи «один-к-одному» встречаются редко. В нашей модели данных их нет.
Если одна сторона имеет степень «один или много», а другая сторона имеет степень «один и только один», то это связь «один-ко-многим» или «1-к-М». Все связи в нашей модели - это связи «один-ко-многим». Этого можно было ожидать, поскольку связи «один-ко-многим» наиболее распространены.
И наконец, последний тип связей - когда обе стороны имеют степень «один-ко-многим». Такого типа связи называются «многие-ко-мно-гим», или «М-к-М». В предыдущей версии нашей модели данных связь Artist-CD имела тип «многие-ко-многим».
Уточнение.связей
Как отмечалось ранее, связи «один-к-одному» очень редки. На практике, если в процессе моделирования вы столкнетесь с такой связью, следует внимательнее изучить свой проект. Такая связь может означать, что две сущности являются на самом деле одной, и если это так, их следует объединить в одну.
Связи «многие-ко-многим» встречаются чаще, чем «один-к-одному». В этих связях часто есть некоторые данные, которыми мы хотим охарактеризовать связь. Взглянем, например, на предыдущую версию нашей модели данных на рис. 2-8, в которой была связь «многие-ко-многим» между Artist и CD. Artist имеет связь с CD, поскольку у исполнителя есть одна или несколько Song на этом CD. Модель данных на рис. 2-9 фактически является другим представлением этой связи «многие-ко-многим».
Все связи «многие-ко-многим» нужно разрешать с помощью следующей технологии:
Почти всегда обнаружатся дополнительные атрибуты, принадлежащие новой сущности. Если это не так, то все равно необходимо разрешить связь «многие-ко-многим», иначе возникнут проблемы при переводе вашей модели данных в физическую схему.
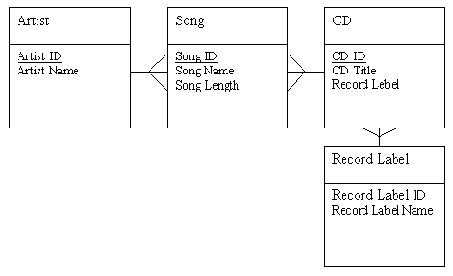
Рис. 2-10. Наша модель данных во второй нормальной форме
Еще о 2NF
Наша модель все еще не приобрела вторую нормальную форму. Значение атрибута Record Label (фирма звукозаписи) имеет только одно значение для каждого CD, но одно и то же значение его присутствует в нескольких СD. Ситуация сходна с той, которая была с атрибутом Band Name. И точно так же дублирование указывает на то, что Record Label должна быть частью отдельной сущности. Каждая Record Label выпускает один или много CD. Каждый CD выпускается одной и только одной Record Label. Модель этой связи представлена на рис. 2-10.
Третья нормальная форма (3NF)
Сущность находится в третьей нормальной форме, если она уже находится во второй нормальной форме и ни один неидентифицирующий атрибут не зависит от каких-либо других неидентифицирующих атрибутов. Атрибуты, зависящие от других неидентифицирующих атрибутов, нормализуются путем перемещения зависимого атрибута и атрибута, от которого он зависит, в новую сущность.
Если бы мы пожелали отслеживать адрес Record Label, то столкнулись бы с проблемами для третьей нормальной формы. В сущности Record Label должны быть атрибуты State Name (название штата) и State Abbreviation (сокращенное название штата). Хотя для учета CD эти данные и не нужны, мы добавим их к нашей модели для иллюстрации проблемы. На рис. 2-11 показаны адресные данные в сущности Record Label.
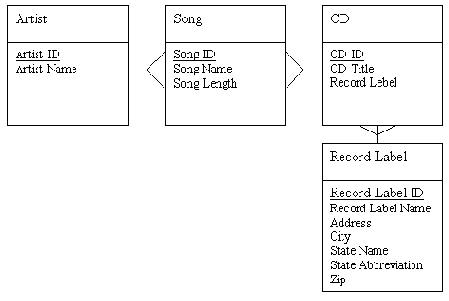
Рис. 2-11. Адресная информация о фирме звукозаписи в нашей базе данных
Значения State Name и State Abbreviation удовлетворяют первой нормальной форме, поскольку имеют только одно значение в каждой записи сущности Record Label. Проблема в том, что State Name и State Abbreviation взаимозависимы. Иными словами, поменяв State Abbreviation для какой-либо Record Label, мы вынуждены будем также изменить State Name. Мы произведем нормализацию, создав сущность State с атрибутами State Name и State Abbreviation. На рис. 2-12 показано, как связать эту новую сущность с сущностью Record Label.
Теперь, получив третью нормальную форму, мы можем сказать, что наша модель данных нормализована. Существуют и другие нормальные формы, имеющие значение с точки зрения проектирования баз данных, но их рассмотрение находится за пределами нашей книги. В большинстве случаев третьей нормальной формы достаточно, чтобы гарантировать правильность проекта базы данных.
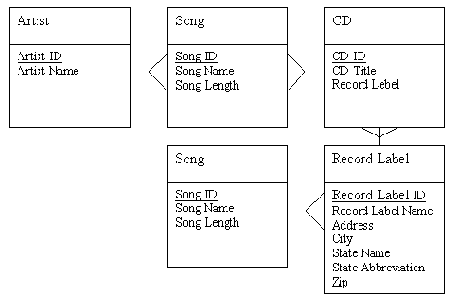
Рис. 2-12. Модель данных в третьей нормальной форме